能夠在惡意軟體一出現時就能夠捉到對保護使用者、社群、企業和政府來說是相當重要的。隨著機器學習(Machine learning,ML)技術被運用在網路安全上,偵測惡意軟體爆發的效率變得更高。

機器學習有助於分析大量資料,找出惡意軟體樣本的模式和關聯性,幫助訓練系統來偵測未來的相似變種。但如果只有少量的資料集,機器學習是否能夠用來分析惡意軟體爆發?我們與澳大利亞聯邦大學的研究人員合作進行一項名為「生成惡意軟體爆發偵測(Generative Malware Outbreak Detection)」的研究,該研究顯示出利用對抗自編碼器(AAE)取得可能表徵能夠有效處理這種情況。這被用來偵測惡意軟體爆發的機器學習(ML)模型使用生成對抗網路(GAN)來透過少量的OS X訓練樣本取得相似的樣本。
大規模的惡意軟體爆發
在今日的威脅環境中,惡意軟體爆發已經成為公開的事件,對全球使用者和企業帶來負面的影響,造成了數十億美元的損失。根據美國政府的說法,2017年的NotPetya勒索病毒成為「史上最具破壞性和代價最高的網路攻擊」。它對政府及企業都造成了嚴重破壞,丹麥航運巨頭Maersk是最知名的的受害者之一。
與此同時,2018年的VPNFilter病毒爆發感染了家庭及小型企業所使用的50萬台路由器,多數受害者位於烏克蘭。這隻多階段的惡意軟體散播到了54個國家/地區,並且跟BlackEnergy間諜軟體有著重疊的程式碼。
這兩個案例都有大量資料可供分析。但對只有少量可用資料的病毒爆發,我們提出了一種作法能夠去偵測近似的惡意軟體變種。此作法只要用一個惡意軟體樣本進行對抗自編碼器(AAE)訓練,對相似惡意軟體樣本有較高的偵測率,對良性樣本有較低的誤判率。
在此研究中,我們收集了3,254個OS X惡意軟體樣本及9,981個隨機的OS X Mach-O樣本。為了複製惡意軟體爆發,3,254個惡意樣本中有175個是病毒專家精心挑選出來具有獨特指令序列模式的樣本。這些被選定的惡意軟體樣本是核心訓練樣本,分配了獨特的標籤。
一個重要的特徵:程式指令序列
惡意軟體作者通常會用客製化工具自動產生變異或修改過的惡意軟體。這些樣本基本上屬於同一組惡意軟體,具備相同的功能,但是利用混淆技術使其看起來不同,用意是要躲避資安產品基於靜態特徵碼的偵測。雖然惡意軟體樣本被混淆過,但我們能夠看到它們仍具備相對不變的特徵:程式指令序列的分佈。
- MAC.OSX.CallMe.A(3個樣本)
- MAC.OSX.CallMe.E(1個樣本)
- MAC.OSX.CallMe.F(1個樣本)
為了說明,我們用下列作法分析了MAC.OSX.CallMe惡意軟體的不同變種:
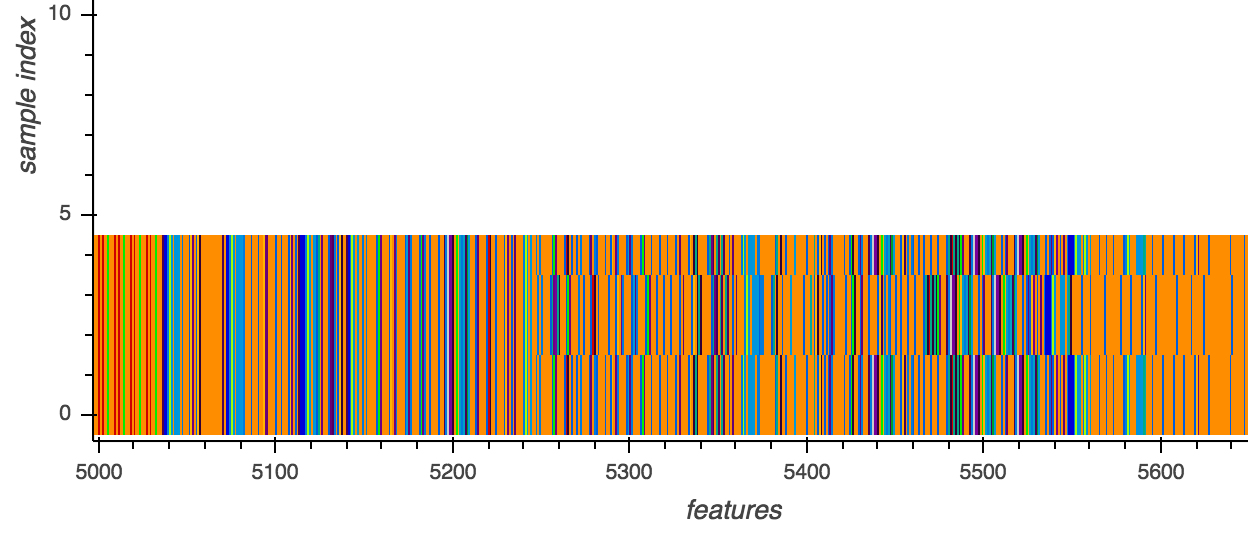
注意:每行代表了一個樣本特徵,它是惡意軟體樣本的一個指令序列。每個正規化指令都化成不同顏色的直條來區分不同指令。X軸表示特徵,Y軸表示樣本編號。
MAC.OSX.CallMe病毒家族三種變種的視覺化分析
我們可以從圖中看出MAC.OSX.CallMe惡意軟體的所有變種都具有相同的指令序列,直到指令5250有了差別。即使出現此不同之處,樣本2和3也只是移動了剩下的指令。這可以看出不同MAC.OSX.CallMe變種的指令序列仍然非常相似。證明了惡意軟體樣本的程序指令序列是在爆發期間識別惡意軟體變種的重要關鍵。
我們的研究報告還探討了用具語意散列的對抗自編碼器(aae-sh)偵測惡意集群的例子 – 該模型偵測到不同長度但包含相似指令序列的Flashback變種。
我們的研究報告「生成惡意軟體爆偵測(Generative Malware Outbreak Detection)」深入探討了如何用指令序列作為我們所提出惡意軟體爆發檢測模型的單一特徵。報告中還探討了我們所提出的模型如何透過對抗自編碼器(AAE)在出現代碼換位和整合變形的情況下捕捉到程式指令序列。此篇報告已經在IEEE的資訊技術國際會議(ICIT 2019)上發表。更新的版本會在IEEE Xplore數位圖書館提供。
@原文出處:Using Machine Learning to Detect Malware Outbreaks With Limited Samples