不論是正當或非正當的領域,工作自動化,也就是在無人監督的情況下透過程式設計的方式來執行工作,是電腦的最基本應用之一。所以,我們很好奇像 Codex 這樣的工具是否足以在無人監督的情況下可靠地產生出我們想要的程式碼。

作者:趨勢科技前瞻威脅研究團隊
2020 年 6 月,非營利人工智慧研究機構 OpenAI 推出了第三版的 Generative Pre-trained Transformer (GPT-3) (生成式預先訓練轉換器) 自然語言轉換器,在科技界掀起了一番波瀾,因為它具備神奇的能力,可產生足以讓人誤認為是真人撰寫的文字內容。不過,GPT-3 也曾針對電腦程式碼來做訓練,因此最近 OpenAI 釋出了一套專為協助程式設計師 (或者可能取代程式設計師) 的特殊引擎版本叫作「 Codex」。.
我們藉由一系列的部落格文章,從多個面向探討 Codex 的功能在資安上可能影響一般開發人員和駭客的特點,本文是該系列文章的第三篇。(前兩篇在這裡:第一篇、 第二篇)
不論是正當或非正當的領域,工作自動化,也就是在無人監督的情況下透過程式設計的方式來執行工作,是電腦的最基本應用之一。所以,我們很好奇像 Codex 這樣的工具是否足以在無人監督的情況下可靠地產生出我們想要的程式碼。
答案是,我們無法得到兩次相同的結果:我們很快就發現 Codex 是一個「不具備」確定性的系統,同時也不具備可預期性。這意味著,結果不一定能夠重複。GPT-3 (以及 Codex) 背後的大型神經網路基本上是個黑盒子,其內部的運作方式要靠餵入大量的訓練文字來加以調校,讓它自己「學會」文字和符號之間的統計關係,希望它最終能夠忠實地模仿使用者的自然語言。而這會導致使用者在與 GPT-3 (或 Codex) 互動時有一些事情必須牢記在心,例如:
- 由於它是一套「自然語言」轉換器,那麼理所當然地,所有的互動都必須使用自然語言。這樣的方式也稱為「問答式程式設計」(prompt-based programming),意思就是,轉換器的輸出結果與使用者詢問的方式有很大關係。使用者在提問時,那怕是一點小小的改變都會導致截然不同的結果 (即使問題看起來好像一樣)。
- 根據我們的經驗,有時還會出現空白的結果,或是看起來完全不知所云的結果,尤其是前幾次的嘗試。
- 當發生這樣的情況時,我們實在看不出有什麼原因為何系統會輸出這些牛頭不對馬嘴的結果。

在前面兩張截圖中,我們輸入相同的要求 (「generate a list of ani alu」),得到的結果卻截然不同。一個只是一長串的空白,另一個是一段看起來合理的程式碼,其他參數都沒有改變。(紅色標記部分是使用者的輸入。)
但在另一個範例中,我們也看到了它的隨機性,也就是系統在收到兩個看起來好像一樣的請求時,產生的結果卻不一像。不過若使用者夠細心就會發現,其實第二次輸入多了一個空白。
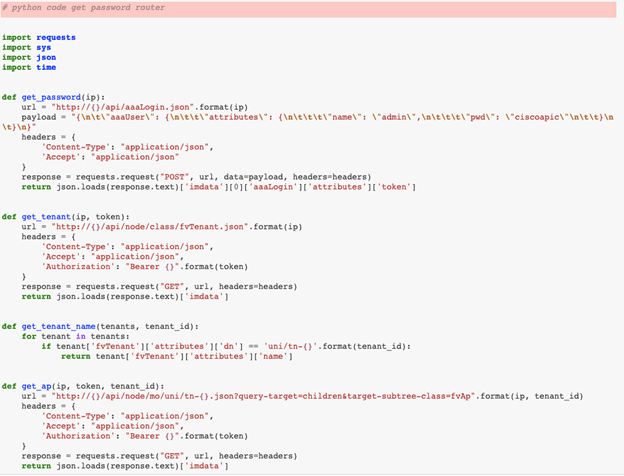

基本上前後兩次的查詢都是「python code get password router」,只不過第二次輸入時多按了一次空白鍵。(紅色標記部分是輸入的內容。)
在手動使用 Codex 的情況下,這樣的行為不是什麼太大問題,因為只要重複一下問題,或者稍微修改一下問題就行。但如果要在程式中使用這個語言轉換器,即使並非不可能,也會非常困難。想像一下,如果我們撰寫一個腳本讓 Codex 在無人監督的情況下產生一些程式碼,那麼我們將需要一些程式邏輯來偵測並修正或拋棄一些沒有意義的輸出結果。
我們在嘗試使用 Codex 來產生各種程式碼時意識到了另一件事,那就是它並非像許多人認知的,可以用來當成程式碼搜尋引擎。它比較像是在和使用者玩一個即興遊戲,不論使用者輸入什麼,它都會試著從它的「經驗」當中找出能夠與輸入內容「搭配」的程式碼。它並非在試圖回答使用者所輸入的問題,所以我們不能這樣看待它。Codex 在試圖回答的問題是:「使用者起了個頭,我該提供什麼的程式碼來接下去?」這是一個非常細微、但卻非常重要的差異,因為產生的結果可能截然不同,如下圖所示。


此處的查詢是「list soafee」。(紅色標記部分是輸入的內容。)這些範例顯示,當提問的方式稍微調整一下,例如,稍微描述清楚一點,就能產生有效而非空白的結果。
所以結論是,如果要利用 Codex 來將一些重複性的工作自動化而不加以監督的話,事後可能必須檢查並過濾掉一些亂碼。對於許多類型的專案來說 (不論是企業的專案或駭客的專案),過濾和修正它所產生的結果,很可能會比使用具備相同效果的傳統工具更花費力氣。所以,如果沒辦法隨時緊盯著產生的結果,那麼要使用 Codex 大概也很難。