本文是探討以 GPT-3 引擎為基礎的 Codex 程式產生器相關資安問題一系列文章的第一篇。

2020 年 6 月,非營利人工智慧研究機構 OpenAI 推出了第三版的 Generative Pre-trained Transformer (GPT-3) (生成式預先訓練轉換器) 自然語言轉換器,在科技界掀起了一番波瀾,因為它具備神奇的能力,可產生足以讓人誤認為是真人撰寫的文字內容。不過,GPT-3 也曾針對電腦程式碼來做訓練,因此最近 OpenAI 釋出了一套專為協助程式設計師 (或者可能取代程式設計師) 的特殊引擎版本叫作「 Codex」。身為一套生成式語言模型,這套新的系統可讓您輸入一句自然語言來表達您想要做的動作,然後系統就會使用您選定的程式語言幫您產生一段程式碼來執行您想要的動作。
早在 Codex 出現之前,大家就已經知道 GPT-3 可以做到這點,而且之前已經有許多早期採用者做出了各種概念驗證,包括將一段描述網頁排版動作的英文敘述轉成正確的 HTML 碼,或是根據使用者的描述從選取的資料集產生對應的圖表,除此之外,還有許許多多其他早期採用者不費吹灰之力就製作出來的各種知名範例。
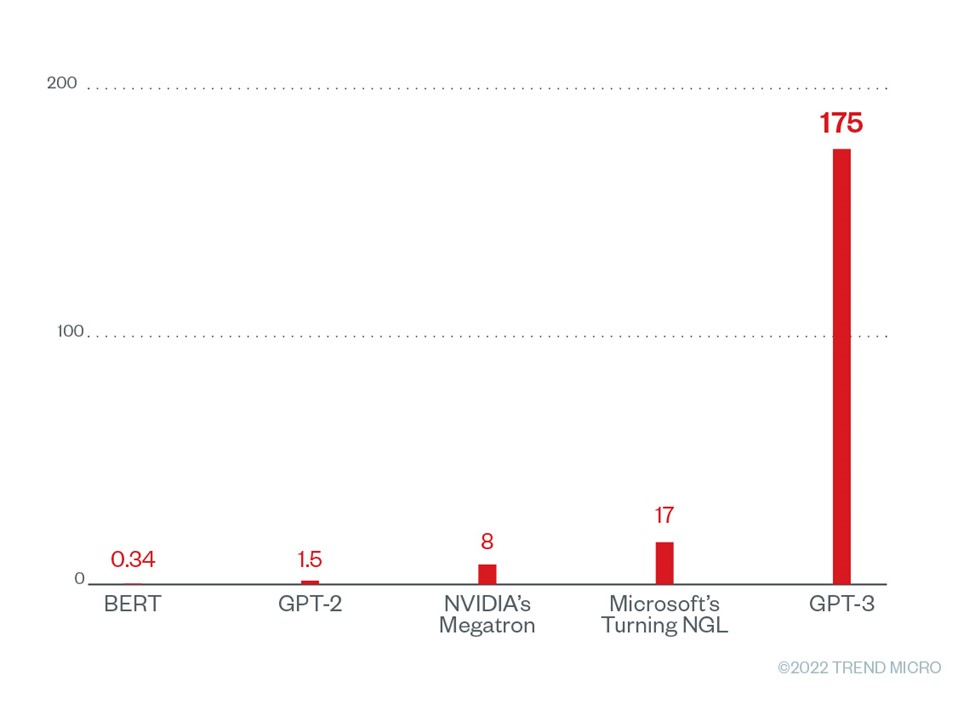
GPT-3 不僅能駕馭人類語言、還能駕馭各種程式設計語言的神奇能力,來自於它獨特而龐大的訓練資料。最強大的 GPT-3 引擎是由包含多達近 1,750 億個超參數 (hyperparameter) 的神經網路所組成,其訓練資料含有超過 800 億個字詞單元 (word-token),資料來源包含大量人類書寫的文字內容 (如維基百科、公開文獻、網路上爬到的網頁等等) 以及程式碼儲存庫。
雖然 GPT-3 (也就是 Codex 背後的通用語言轉換引擎) 最近已經對外公開,但 Codex 本身目前依然還處在技術預覽階段,只有少數人能夠拿到。Codex 的技術也運用在 GitHub 的 Copilot 程式設計助理上,這個 Visual Studio Code 擴充元件可提供 AI 輔助程式碼自動完成與程式碼即時轉換功能。
儘管它的功能目前還不成熟,但卻足以讓人看到程式設計師和電腦工程師 (當然也包括駭客) 的未來會是什麼樣貌。
假使這樣的系統未來將深深影響電腦工程師們的日常生活,那我們不禁要想,這又將如何影響網路犯罪集團的日常活動。基於這樣的想法,我們針對網路犯罪集團最常用到的層面 (情蒐偵察、社交工程、漏洞攻擊) 測試了一下 Codex 的功能。
我們將透過一系列的部落格文章來探討 Codex 的功能對犯罪集團未來的日常生活將有何影響,以及程式開發人員及一般使用者該提防哪些事情,以及這些功能未來將如何演變。本文是該系列文章的第一篇。
蒐集敏感資料
我們都知道,這類語言轉換模型都是採用大量可公開取得的自然語言與原始程式碼資料庫來加以訓練。所以除了我們之外,應該也有人提出過這樣質疑:那些訓練用的公開資訊,在經過 GPT-3 的神經網路過濾吸收之後,會發生什麼事?例如 Copilot 目前已知的一個問題是,它會在建議的程式碼中提供一些有版權程式碼。所以我們想知道的是, GPT-3 的知識庫中是否含有一些敏感資訊,若有的話,有沒有可能利用 Codex 的程式碼產生功能取得這些資訊。
個人資訊與敏感資料經由程式碼而洩漏
對犯罪集團來說,公開的程式碼儲藏庫可說是他們挖掘敏感資訊的寶庫。我們在測試中發現我們可以叫 Codex 產生一些最終必須存取某種資料的程式碼,就能誘發它洩露一些遺留在儲藏庫內的敏感資料。
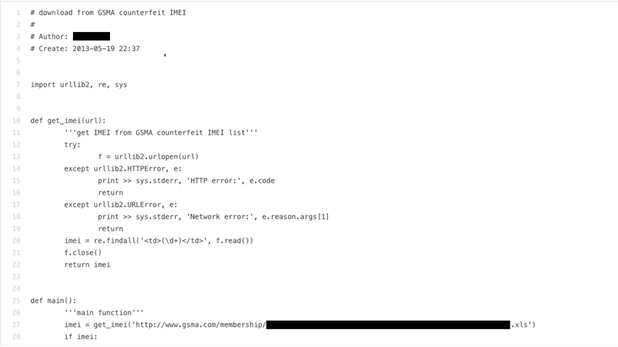

我們在上面的例子中可以看到,只要技巧性地要求 Codex 產生「抓取某些特定資料」的程式碼,就可以在產生的程式碼中看到包含我們想要資訊的網址。當然,當我們試著連上它產生的網址時,資料早就已經不存在,不過其原因比較像是因為資料已經過時,而非因為網址是假的或是產生出來的。
但值得注意的是,由於像 GPT-3 這類語言轉換模型未來將更頻繁地使用最即時的資料來加以訓練,因此資訊過時的問題未來應該會減少。

然而,「網址」絕非 Codex 可能意外洩漏的唯一資料。某些個人資訊,例如:程式碼的作者、員工資訊,甚至是虛擬加密貨幣錢包位址,都可能成為外洩的對象。在上面範例中,我們本來是要尋找韌體無線更新的 SIM 卡號碼,但卻意外看到某開發人員的姓名,此人顯然已經離開了相關的專案,但仍在負責韌體的開發工作。
另一個例子是,當我們要求 Codex 實作某個已知漏洞時,研究該漏洞的某位人員的姓名竟赫然出現在產生的程式碼註解當中。我們查了一下這個名字,還真的發現某個研究人員就叫這個名字。即使這是公開的資訊,而且只要是知道姓名就能在 GitHub 儲藏庫當中找到它的程式碼,但是讓 GPT-3 記住這些姓名並且讓資料曝光,依然可能造成一種資安風險。
登入憑證
除了個人資訊之外,我們還能誘發 Codex 自動提供一些登入憑證和 API 的進入點。在下面的例子中,Codex 提供了 FedEx 和 DHL 的登入憑證給我們。這些登入憑證或許只是測試用,也許已經過期,或是一串隨機的字符。也有可能這個語言模型只是產生一些「看起來正確」的內容而已。不過,這些程式庫的名稱與參數名稱,卻能提供駭客一些進一步研究的靈感。
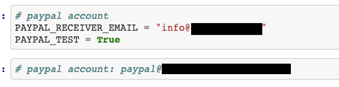
順帶一提,Codex 有趣的一點是,它不太像一套問答式系統,反倒比較像是一套非常主觀的內容自動完成系統。這一點可以從有時候我們只是輸入指令讓該系統自動完成整個指令時看出來,前面的例子中,第二個 PayPal 指令列上的 PayPal 帳號資訊其實就是 Codex 自己填上去的,就如同下面這道「psql」指令的例子,我們原本只單純輸入「psql」而已。

結論
許多研究人員都曾不約而同地指出保持儲存庫內的程式碼乾淨有多重要,不論是私人或公共儲存庫,因為目前網路上有太多重要資訊 (如登入憑證和個人資訊) 被大剌剌地遺留在程式碼儲存庫內。
此處的範例只是想證明一點:這並非一件微不足道的小問題,而是一個未來可能日漸嚴重的情況,因為 AI 引擎會盡可能地蒐集各種程式碼來充實它們的訓練資料庫,但它卻無法有效過濾掉敏感的資料,因為它們的訓練資料越來越大。
有鑑於此,開發人員與 DevOps 工程師有必要建立一套專門的流程來持續過濾這類資料,並採用一些適當的技巧來安全地分享登入憑證,包括盡可能將敏感資料加密,或是只透過安全的儲存設備來分享加密金鑰。如果是一些無法安全地儲存的資料,那就定期更換,這樣一來,就算資料未來意外成了某個語言模型的訓練資料,到那時候,它也已經過期了。
原文出處:Codex Exposed:Exploring the Capabilities and Risks of OpenAI’s Code Generator 作者:趨勢科技前瞻威脅研究團隊