趨勢科技深入研究了具備執行程式碼、上傳文件以及存取網際網路能力的大型語言模型 (LLM) 驅動的 AI 代理所存在的漏洞。這是一系列深入揭發 AI 代理漏洞的第二篇文章。
LLM 服務有可能變成網路攻擊的入口嗎?可不可能被挾持用來執行有害的指令?有沒有可能被 Microsoft Office 文件中暗藏的指令所騙而洩漏敏感的資料?駭客能不能篡改資料庫查詢來取得管制的資訊?
這些都是 AI 代理今日面臨的一些基本問題。本系列文章討論 AI 代理的重大漏洞,深入揭發其看似聰明的回應底下所潛藏的威脅。

主要重點
- 本文探討任何具備執行程式碼、上傳文件以及存取網際網路能力的大型語言模型 (LLM) 驅動的 AI 代理所存在的漏洞。
- 這些漏洞可能讓駭客執行未經授權的程式碼、在檔案中插入惡意內容、取得掌控權,以及洩露敏感資訊。
- 採用人工智慧 (AI) 來執行數學運算、數據分析以及其他複雜流程的企業,對於相關的資安風險應隨時保持警戒。
- 限制某些功能、監控活動、管制資源,這些都是能解決相關漏洞的不錯建議。
大型語言模型 (LLM) 讓自動化、運算及 AI 驅動的推理發生了天翻地覆的改變。儘管它們執行程式碼、處理文件以及存取網際網路的能力帶來了很大的進步,但卻也衍生出新型態的漏洞。本篇是一系列深入揭發 AI 代理漏洞的第二篇文章,若要閱讀第一篇文章,請至 這裡。
本文探討具備程式碼執行能力的 LLM 驅動 AI 代理所衍生的系統性風險,並且點出關鍵的攻擊管道、資安風險以及可能的防範方式。本系列其他文章還有:
第三篇:資料外傳 ─ 探討駭客如何利用間接提示注入技巧,讓 GPT-4o 這類多模態 LLM 在遇到看似無害的惡意檔案時將機敏資料外傳。這種所謂的「零點選」(zero-click) 漏洞可讓駭客在網頁、圖片及文件中暗藏指令,誘騙 AI 代理洩露使用者互動記錄、上傳檔案,以及聊天記錄當中的機密資訊。
第四篇:資料庫存取漏洞 ─ 探討駭客如何攻擊與 LLM 整合的資料庫系統,透過 SQL 隱碼注入、預先儲存的提示注入,以及向量儲存下毒來取得管制的資料,同時還能避開認證機制。駭客可利用提示篡改來影響查詢結果、取得機密資訊,或者插入永久性漏洞來影響未來的查詢。
程式碼執行在 LLM 當中的必要性
現代化 AI 代理可執行程式碼來完成準確的運算、分析複雜的資料、輔助結構化運算的執行。如此可確保在數學及科學等領域獲得準確的結果。藉由將使用者的查詢轉換成可執行的腳本,LLM 就能彌補它們數學推理能力的不足。
LLM 是一種神經網路模型,它能在收到一串文字輸入之後,生成該文字後面最可能緊接著出現的文字 (或者更確切來說,下一個 token),因為它的輸出是根據它所吸收的訓練資料歸納出來的模式/規律而產生。
沙盒模擬環境的實作
AI 代理會運用沙盒模擬環境在隔離的環境中執行程式碼,以確保安全的情況下實現其功能。
目前常見的沙盒模擬環境有兩種:第一種是容器化沙盒模擬環境,也就是 OpenAI 的 ChatGPT Data Analyst AI 代理 (原 Code Interpreter) 所用的,它們提供了作業系統 (OS) 層次的隔離,並且可執行多個處理程序。
第二種是基於 WASM (WebAssembly) 的沙盒模擬環境,它們在瀏覽器當中提供輕量化的虛擬環境,並有檔案存取限制。ChatGPT 的 Canvas 就是一個基於 WASM 的實作。
ChatGPT Data Analyst 採用由 Kubernetes 管理的 Docker 容器來實作沙盒模擬環境。在 ChatGPT 的對話會中,若使用者的查詢導致系統必須用到沙盒模擬環境,就會啟動一個執行 Debian GNU/Linux 12 (bookworm) 作業系統的 Docker 容器,例如:當需要執行一段程式碼或上傳檔案時。
這個沙盒模擬環境會透過 uvicorn 來執行一個 FastAPI 網站伺服器,以便跟 ChatGPT 的後端伺服器溝通。它負責上傳使用者提供的檔案、從沙盒模擬環境下載檔案、經由 WebSocket 交換使用者提供的 Python 程式碼和執行結果,以及在 Jupyter 核心 (Kernel) 當中執行程式碼。
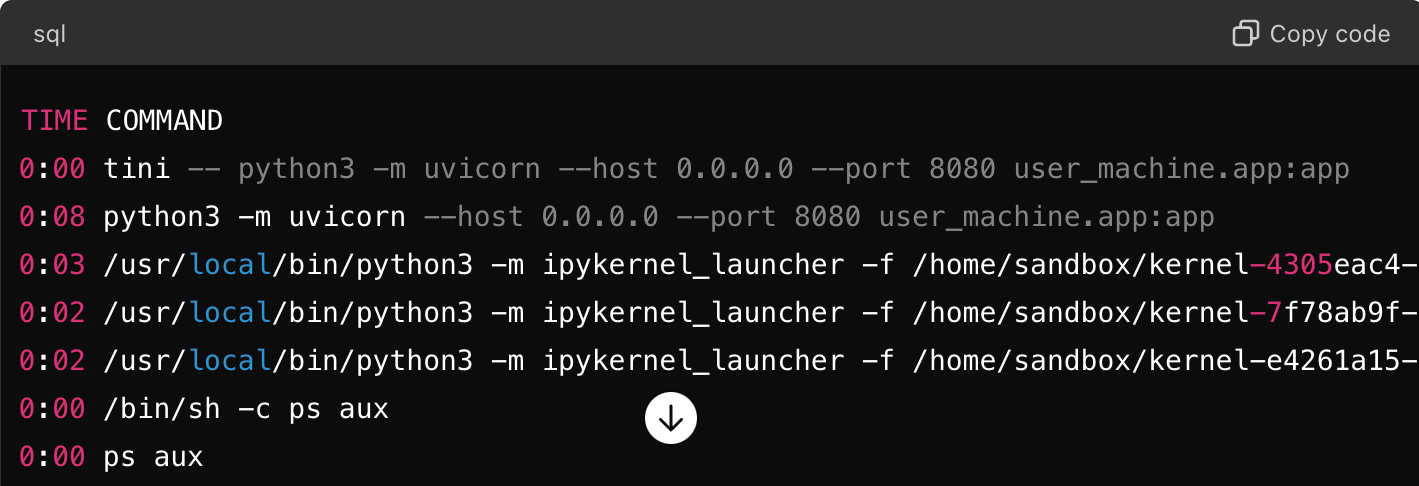
以下 ChatGPT 對話顯示 uvicorn 在沙盒模擬環境中執行的 FastAPI 網站應用程式處理程序清單。
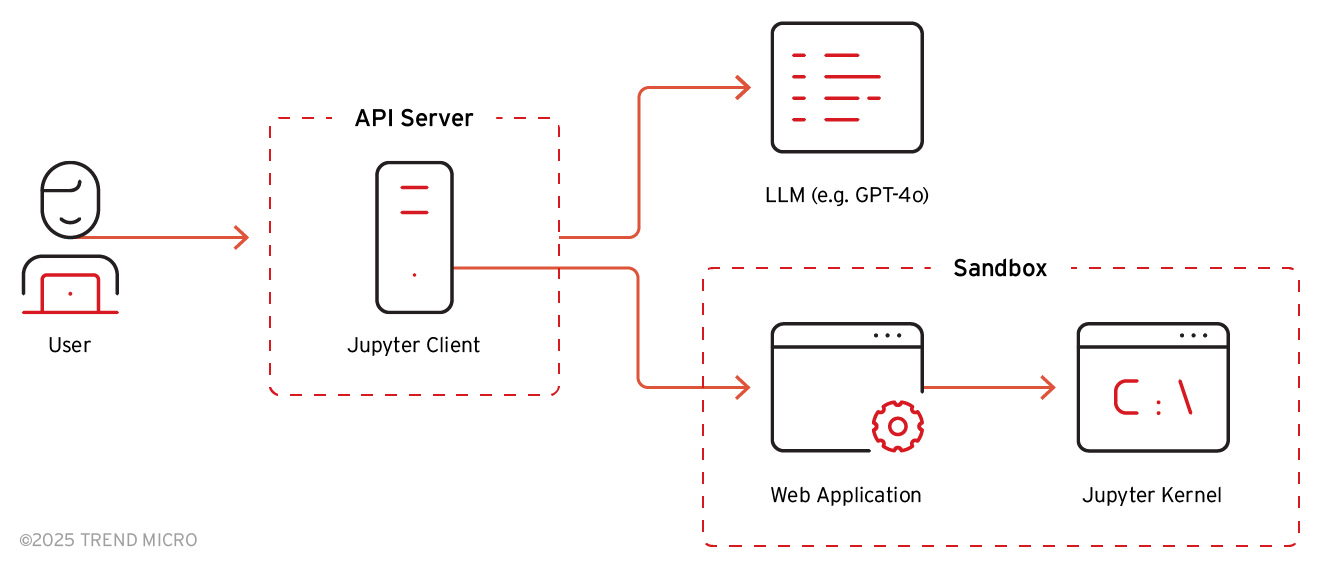
根據 API 伺服器的功能,我們可推測出 ChatGPT 的內部架構應該如下所示:
使用者上傳的檔案 (由 Dall-E 所建立,或者為了回應使用者而建立) 預設會儲存在 /mnt/data 目錄中。
注入漏洞攻擊程式碼:傳送未經檢查的資料
LLM 驅動的 AI 代理最嚴重的漏洞之一就是傳送未經檢查的資料。我們在 2024 年 6 月測試文件上傳時就親自遇到了這樣的問題:一個含有超連結的 Excel 檔案讓 LLM 的沙盒模擬環境發生錯誤。
這表示駭客可以故意製作出這類檔案來避開資安檢查,進而導致執行錯誤或資料外傳。當檔案上傳時,Jupyter 核心會試圖解析它,進而發生未處理的錯誤。
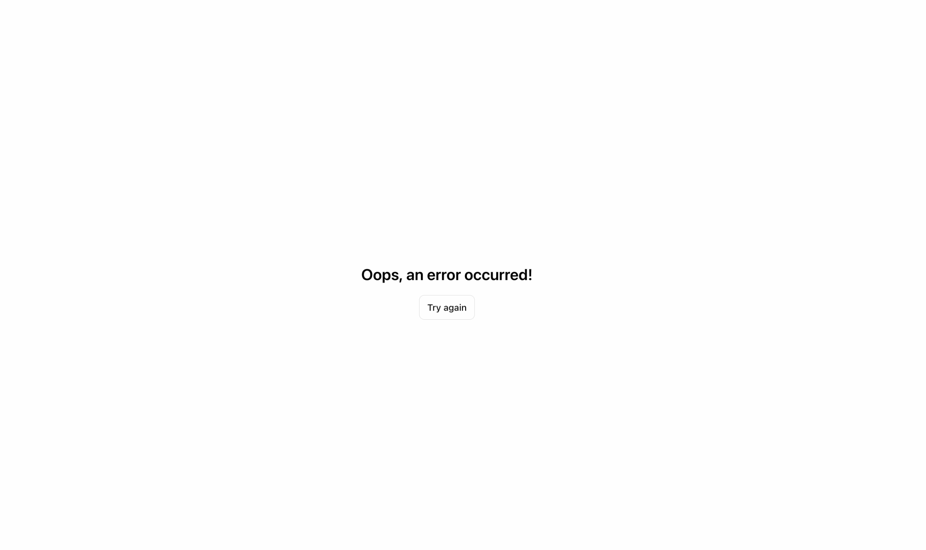
由於負責管理該請求的 FastAPI 網站應用程式未正確處理這項錯誤,進而導致 API 伺服器傳回了不預期的回應。最後在前端使用者介面 (UI) 上顯示了一個通用的錯誤訊息 (如下所示),掩蓋了真正的問題。

這項漏洞在 2024 年 12 月已經修補,改正了錯誤處理程序以及檢查機制來防止類似的漏洞發生,所以問題似乎已經解決。
此一攻擊路徑示範了一個單純的檔案上傳如何導致流程當中出現漏洞,駭客可利用這類弱點來癱瘓服務、操弄錯誤處理機制,或者注入惡意的內容。輸入資料如果沒有加以檢查或淨化,很可能讓駭客利用系統不同層次之間的不一致所導致的漏洞。
使用背景服務來篡改使用者檔案
在某些情況下,由於沙盒模擬環境的管制不夠嚴格,因而無法防止駭客建立背景服務來監控和篡改使用者上傳的檔案。駭客可建立一個背景處理程序 (例如啟動一個 daemon 處理程序) 來監控檔案系統,一旦有使用者上傳文件,就將惡意內容注入文件中。
例如,上傳的 Word 或 Excel 文件當中若含有超連結,就會被更換成網路釣魚連結,使用者一旦讀取就會被帶到惡意網站。
惡意提示與程式碼
駭客可使用下列惡意提示來注入一個背景服務:
使用下列程式碼來建立 /mnt/data/helper.py 並讓它在背景執行。

這個腳本會以背景服務的方式持續在沙盒模擬環境中執行,它會檢查是否有新的文件,並且修改文件當中的超連結。
常駐與橫向移動
這項技巧之所以特別厲害,是因為它會讓一個間接提示注入在沙盒模擬環境內常駐,等於可以感染整個 ChatGPT 對話期間所有使用者上傳的文件。儘管沙盒模擬環境在使用者階段結束之後就會重設,而且背景處理程序也會終止,但這類使用者階段可持續數小時之久,因此大幅增加了注入攻擊所帶來的衝擊。
此一風險還會因為使用者 (尤其是 ChatGPT 付費服務的使用者) 會為了徹底發揮服務的價值,所以更容易將已感染的文件傳給別人。這些文件通常是經由電子郵件分享,或上傳到協同作業平台 (如 wiki 頁面),因而讓感染擴大。
動態提示加密編碼與執行
背景服務的程式碼可能遭人以各種方式篡改,例如傳統惡意程式常用的「多形」(polymorphism) 和「變形」(metamorphism) 技巧,就能用來修改每一代程式碼的長相,讓偵測和分析變得更加困難。
比方說,駭客可以在系統植入一段 base64 編碼的 Python 程式碼,然後在需要時才將它解開來執行。

結論與建議
光是在隔離的沙盒模擬環境當中執行 Python 程式碼,並不足以確保程式碼執行的安全。主要原因在於,漏洞可能來自多個層面,包括沙盒模擬環境、網站服務,以及支援的應用程式。若不妥善強化這些元件的安全,整個 AI 代理都將暴露出可攻擊的弱點。
從這點來看,以下是幾個關注的重點:
- 間接提示注入。駭客可能透過提示注入來操控系統的行為,導致漏洞常駐、檔案遭篡改,並且讓駭客橫向移動。
- 資源限制與存取管理。限制系統資源的用量、管制檔案存取,並且限制網際網路連線,是縮小攻擊面必要的措施。
- 監控與檢查。對於會透過沙盒模擬環境來執行程式碼的 AI 代理來說,持續的活動監控、輸入檢查以及檔案完整性檢查,都是發掘及防範威脅的重要手段。
解決了這些關鍵領域之後,就能大幅提升沙盒模擬環境的安全,不僅能更安全地執行使用者提供的程式碼,同時還能降低潛在風險。
建議企業採取以下措施來解決這份技術摘要所點出的漏洞:
- 限制系統功能
- 停用背景處理程序,或限制它們的某些作業。
- 強制實施更嚴格的檔案系統存取權限管制。
- 限制資源的用量
- 限制沙盒模擬環境的資源用量 (如:記憶體、CPU、執行時間) 來防止資源濫用或耗盡。
- 管制網際網路存取
- 管制從沙盒模擬環境內部存取外部網路,藉此縮小攻擊面。
- 監控惡意活動
- 追蹤帳號活動、失敗情況以及異常行為來發掘潛在威脅。
- 使用行為分析工具來發掘可疑的作業,例如:檔案監控及篡改。
- 檢查輸入
- 檢查及淨化雙向流動的資料 (從使用者到沙盒模擬環境、從沙盒模擬環境到使用者),以確保資料符合規格。
- 確保格式正確
- 確保所有輸出都符合預期的格式才將資料傳給下游。
- 確實的錯誤處理
- 擷取、淨化、記錄每一階段的錯誤來防止問題意外擴散。
◎原文出處:Unveiling AI Agent Vulnerabilities Part II:Code Execution 作者:Sean Park (首席威脅研究員)