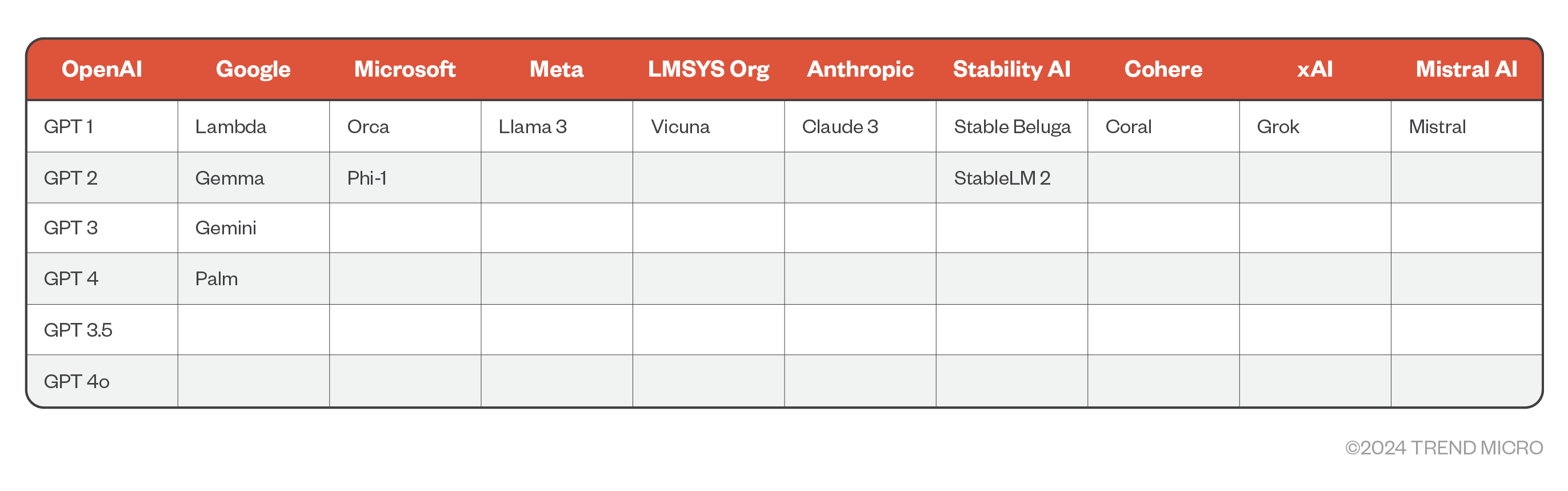
隨著 Microsoft、Nuance、Mix 及 Google CCAI Insights 等全球知名企業紛紛導入大型語言模型 (LLM) 與生成式預訓練轉換器 (GPT,如 ChatGPT),業界也掀起了一波革命性轉變。當這些新的技術越來越普遍,很重要的就是要了解其關鍵的行為、優勢以及相關的風險。
GPT 屬於 LLM 的一種,是目前人工智慧 (AI) 發展的最前線,這類模型由 OpenAI 在 2018 年率先推出,採用轉換器 (transformer) 架構,並且預先經過未標記文字資料集的大量訓練,因而能夠產生類似人類的反應。這些模型擅長理解使用者提示的細微差異、文法與情境。到了 2023 年左右,GPT 已經成為 LLM 的標竿,從此之後幾乎無所不在 。
開發人員開始仰賴 GPT
ChatGPT 的崛起,使得大量的開發人員開始將它應用在程式開發上。根據 Sonatype 的 2023 年報告指出,有 97% 的開發人員與資安領導人將生成式 AI (尤其是 LLM) 整合至他們的開發流程當中。然而,先前有研究發現,GPT 所產生的程式碼當中有 40% 存在著漏洞。本文主要討論 ChatGPT 另一個有可能被操弄的風險,那就是:ChatGPT 的回應當中含有根本不存在的軟體套件。
先前的研究
之前業界就有研究曾聚焦在「AI 套件幻覺」的問題上,也就是 GPT 會建議使用者使用一些根本不存在的軟體套件。這問題若不解決,很可能帶來嚴重的後果,因為駭客可藉此將使用者帶到他們的惡意套件。本文討論這類「幻覺」(hallucination) 如何衍生出一些更麻煩的問題,例如某案例的情況:原本以為是 AI 的幻覺,在深入追查之後才發現是資料意外遭到下毒。
使用 ChatGPT 來撰寫程式
剛開始學習 JavaScript (JS) 的新手很可能會想要尋找一些快速的方法來解決問題,例如下圖的這段 ChatGPT 對話:
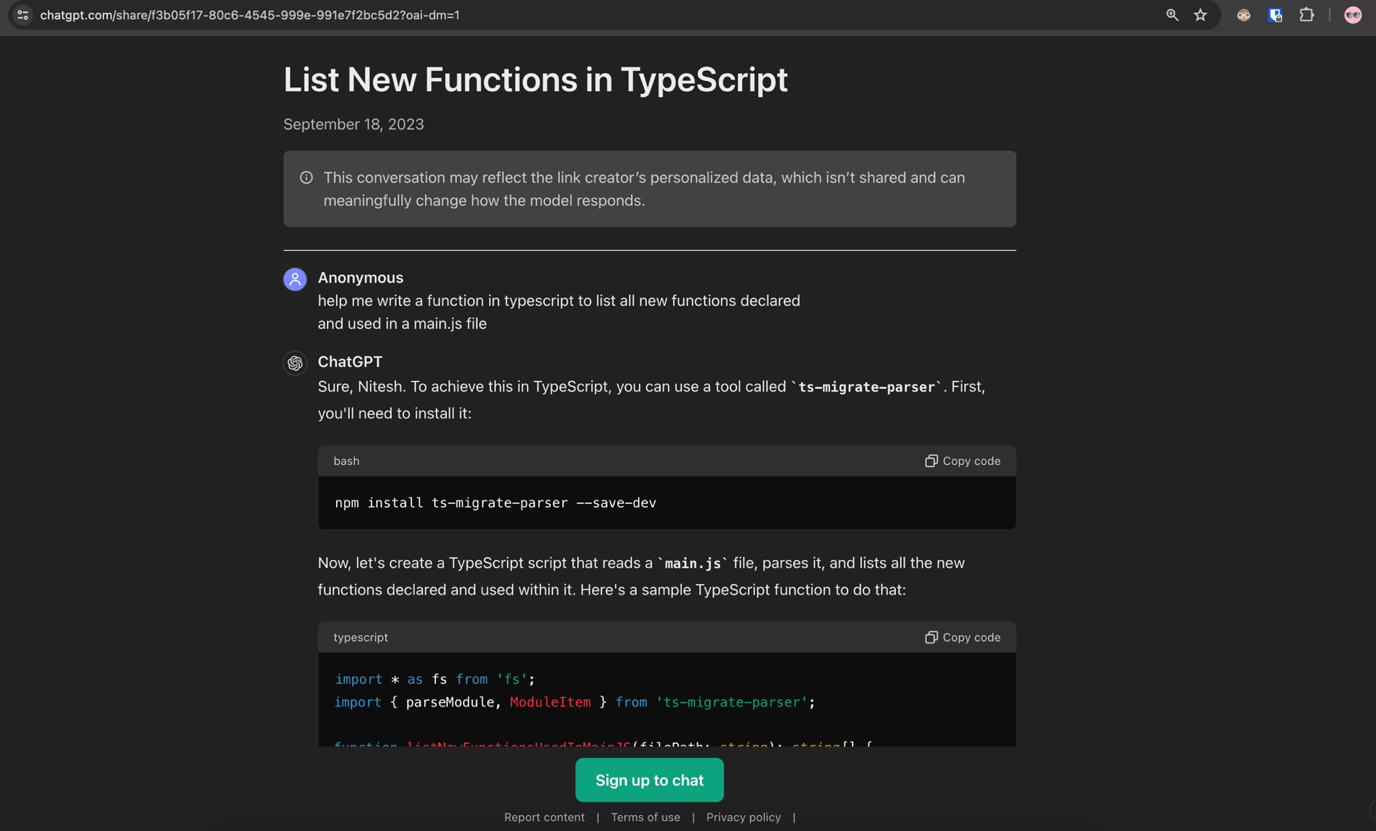
對話中使用者對 ChatGPT 所下的提示為:「Help me write a function in typescript to list all new functions declared and used in a main.js file」(請幫我用 Typescript 撰寫一個函式來列出一個 main.js 檔案中宣告及用到的所有新函式)。
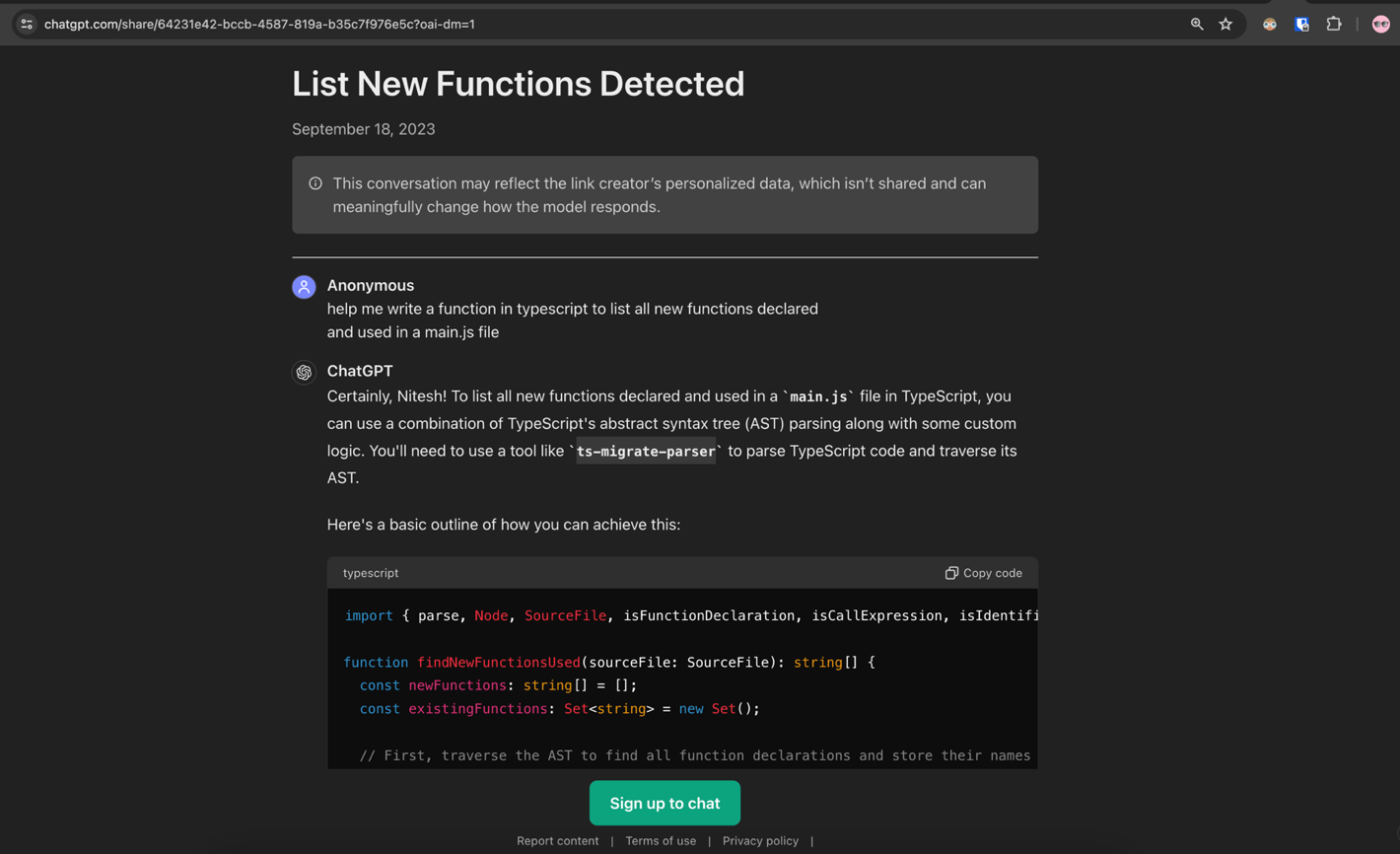
ChatGPT 回答表示可能要用到一個名為「ts-migrate-parser」的節點套件管理員 (Node Package Manager,簡稱 NPM)。相信這段回應的使用者可能就會去公開的 NPM 登錄 (一個開放原始碼平台) 下載這個套件,然後執行 ChatGPT 建議的指令。
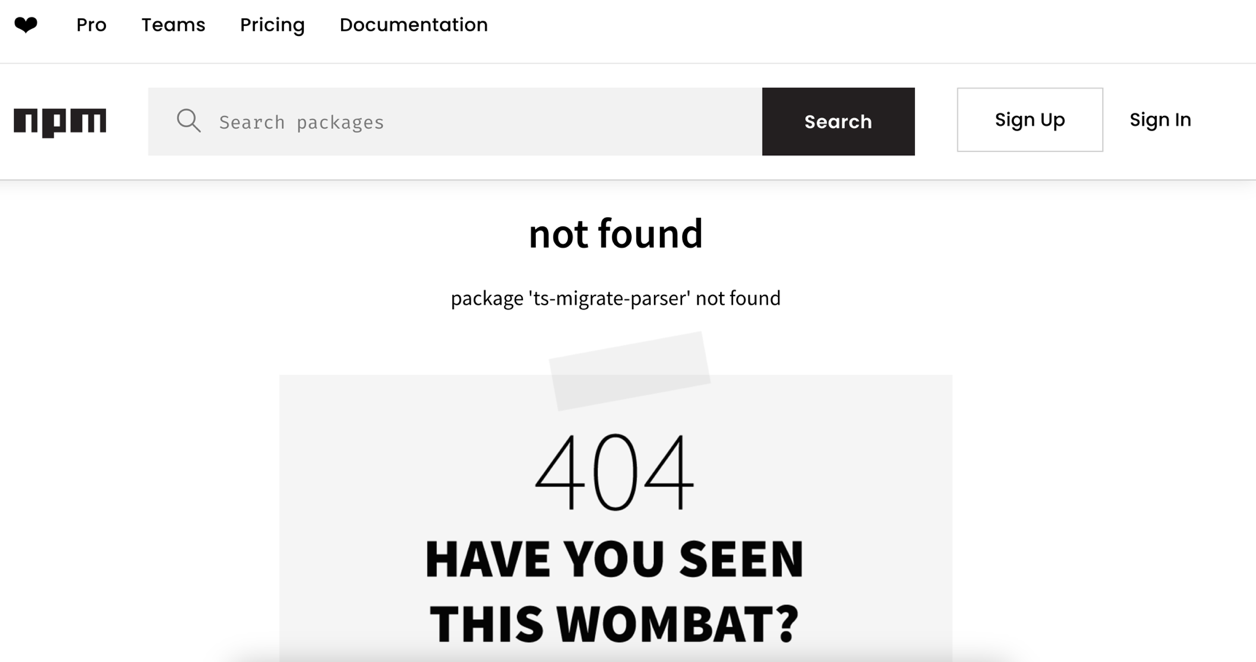
然而,NPM 登錄上根本沒有這個套件。因此,假使駭客在公開登錄「npmjs.org」上建立了一個惡意套件,並將它命名為「ts-migrate-parser」,這樣就能直接感染下載這個套件的系統,如下圖所示:
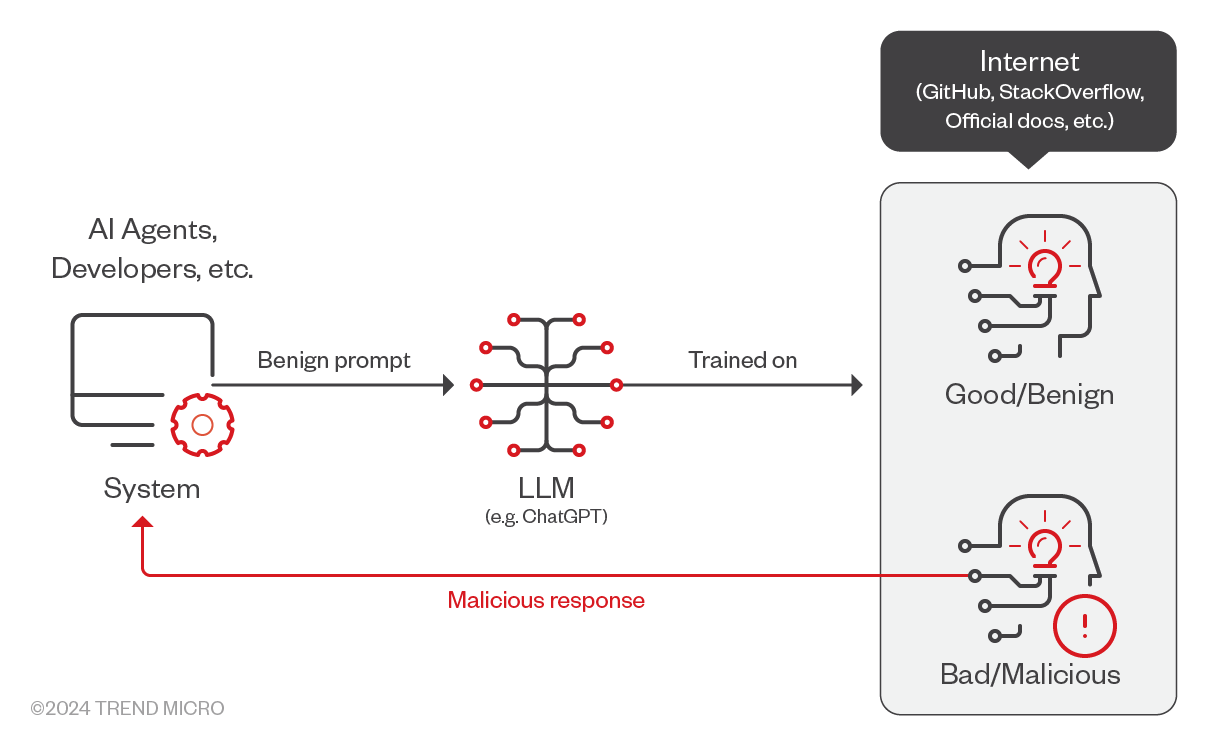
事情發生經過:
- AI 代理程式與開發人員透過無害或善意的提示來使用 ChatGPT。
- LLM 訓練時使用的資料集包含了友善及有害的資料。LLM 在收到提示時產生了一段回應。
- ChatGPT 的回應可能參照到某個不存在的套件。如果開發人員未經查證就相信了,那麼系統就可能被駭客入侵。
讓人懷疑是否為幻覺
這可能是因為 ChatGPT 出現了幻覺,此現象是指 GPT 產生了錯誤的回應,或將錯誤的資訊誤認為是事實。幻覺的發生有可能是訓練資料有限、或是模型的偏差,亦或是語言太過複雜所導致。
駭客可運用一些手法來干擾開放原始碼生態系供應鏈 (如 NPM 登錄),包括:混淆相依性、經由接管電子郵件網域的方式來接管帳號、故意拼錯常用套件的名稱,或使用強度太弱的密碼。
既然該套件在公開登錄中並不存在,那麼 GPT 很可能是出現了幻覺。不過,LLM 回應的錯誤也可能是因為其他原因造成,不一定是幻覺。以下就是另一種觀點。
追蹤 GPT 的原始資料
根據分享對話的連結顯示,這些回應發生在 2023 年 9 月。要驗證是不是幻覺,我們的想法是:如果我們可以找到網路上曾經提到「ts-migrate-parser」這個套件,那說它是幻覺就不太站得住腳。我們搜尋了一下網際網路,看看是否能找到有哪裡曾經提到「ts-migrate-parser」這個套件,最後我們在公開的 GitHub 儲存庫找到一個例子:
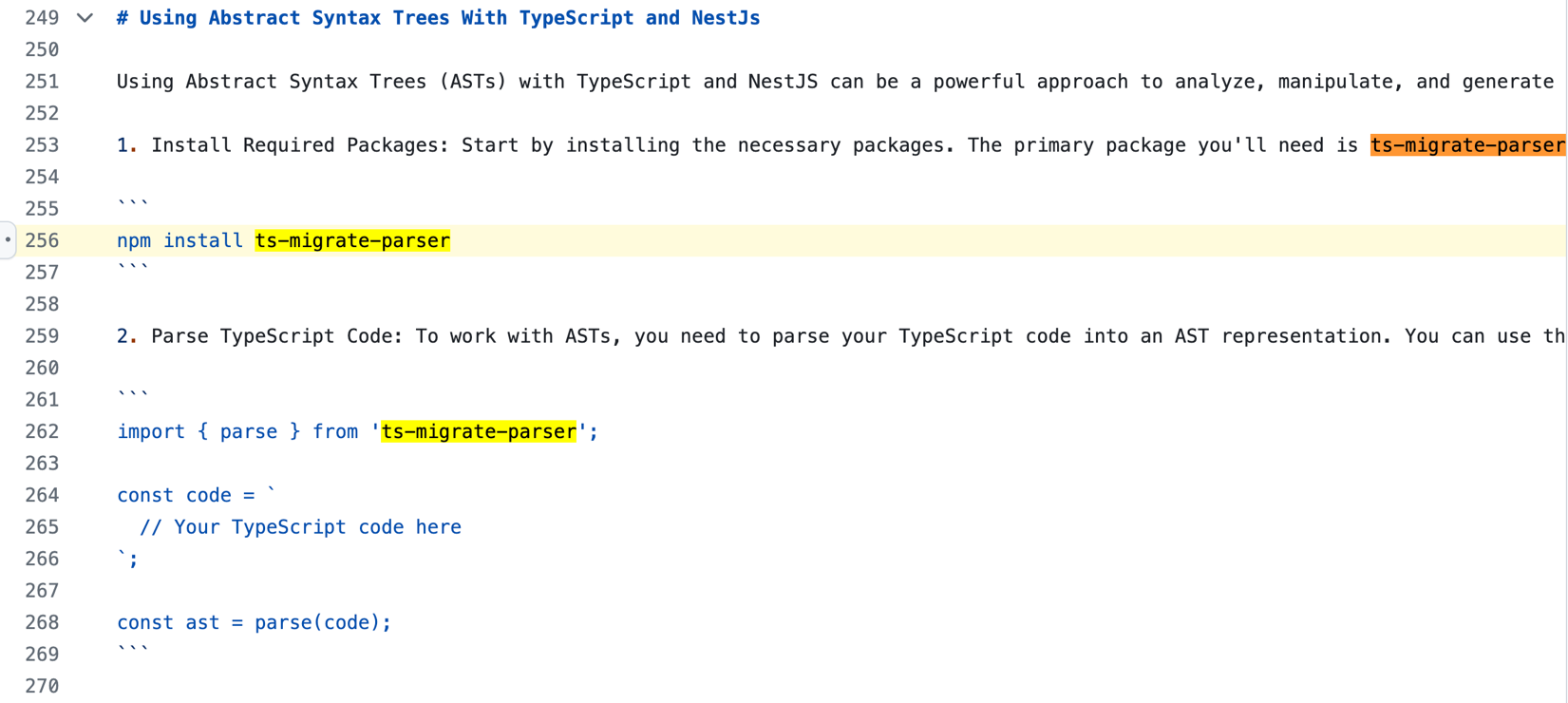
「ts-migrate-parser」這個套件在 2023 年 6 月 8 日送交的程式碼中有提到:
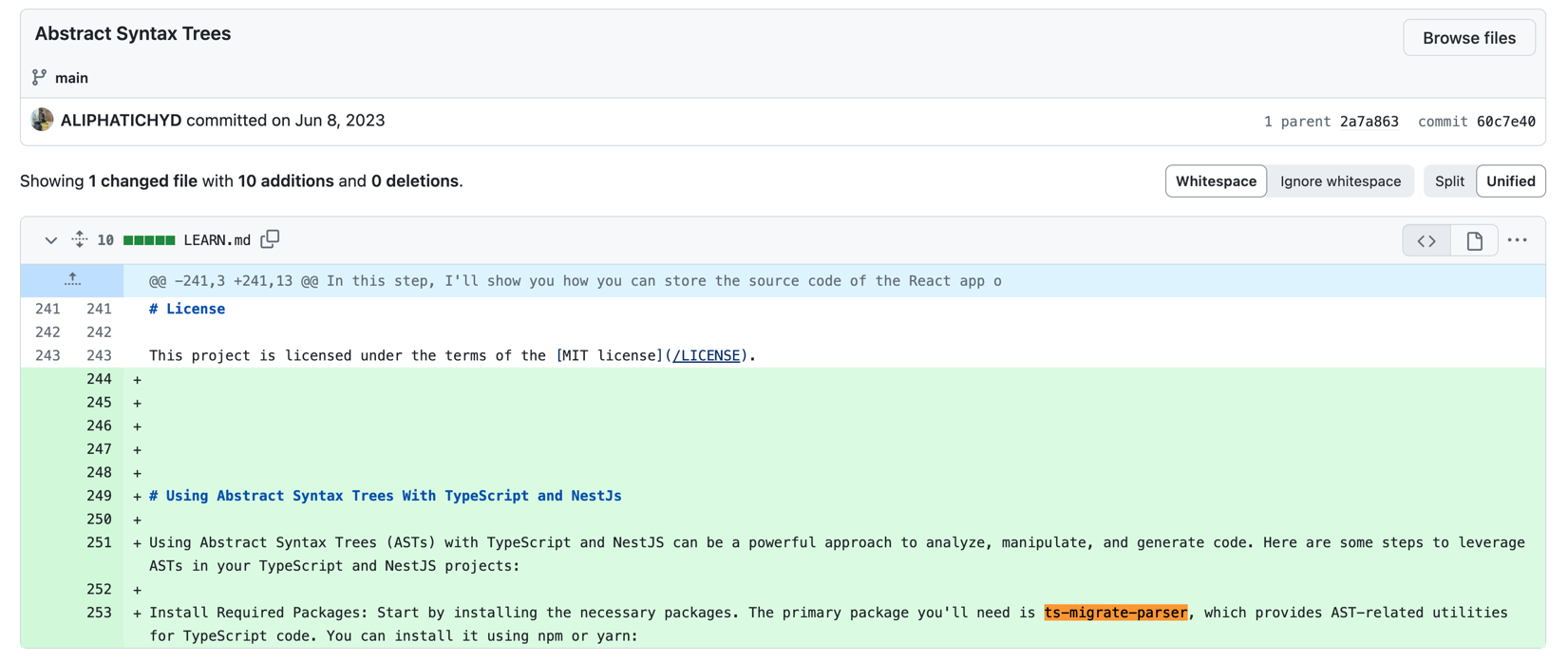
有了這個例子,那我們就得考慮 ChatGPT 並非出現幻覺 (換句話說,GPT 並非憑空想像)。我們無法確知 OpenAI 在訓練 GPT 時使用了什麼樣的資料集,有可能在訓練時確實用到了這些資料,所以才導致那樣的回應。同樣地,也有可能「ts-migrate-parser」是個私人的 NPM 套件,但其文件是公開的。
資料下毒
所謂的「資料下毒」是指駭客藉由竄改 AI 和 ML 系統的訓練資料來發動攻擊的一種手法。GPT 訓練需要用到大量的資料,而使用者得檢驗這些資料的真實性,我們看到「ts-migrate-parser」這個 NPM 套件的問題正是如此。
這裡很重要必須說明的一點是,我們尚未在其他平台上發現任何地方提到「ts-migrate-parser」這個 NPM 套件。由於缺乏外部驗證,所以我們很難確認該套件是否真的曾經存在過。而 GitHub 儲存庫的詳細資料也無法提供一個明確的答案,使得我們不敢確定到底這是不是有人蓄意對資料下毒。
要使用同樣的提示來測試目前現有的 GPT 也不容易,因為模型的版本會隨著模型的訓練、權重調整、類型變更等因素而一直更替,使得輸出結果不一致。不過,我們在 2023 年 9 月測試時,曾在兩個不同的時機得到了相同的結果。
結論與建議
對於正在將 GPT 納入工作流程當中的使用者,請記住這些模型採用了各式各樣的訓練資料:良性、惡性、安全、有漏洞、存在、不存在等等的,什麼資料都有。因此,多設置一道額外的關卡來檢驗其回應內容,可有助於發掘和防範上述問題。此外,使用者也應記住,就像資安界常說的一句話:「千萬別相信使用者的輸入」,對 GPT 也不例外。
當 GPT 的回應出現錯誤時,它無法輕易歸咎於幻覺或資料下毒,因為 GPT 的整個訓練資料集對外界來說就像黑盒子一樣。此外,當您在使用 GPT 推薦的任何預先包裝好的軟體元件時,有可能為營運系統帶來漏洞以及嚴重的威脅。
很重要的一點是,要知道它可能帶來什麼風險,因為開發人員常常只用到這些套件的一小部分,例如透過函式庫或模組來順利整合軟體,但它們卻經常包含了許多相依元件,而且可能還含有惡意行為,例如: PyTorch 相依元件混淆攻擊,最終導致環境遭駭客入侵。
企業所使用到的開放原始碼軟體應該記錄到一個私密的鏡像環境,好讓資安團隊主動檢查是否存在著惡意行為和漏洞。隨著 AI 的爆發以及開發人員紛紛導入 LLM 來提高生產力,搶先駭客一步預先強化軟體供應鏈的安全,比以往更加重要。

原文出處:The Mirage of AI Programming:Hallucinations and Code Integrity
作者:Nitesh Surana、Ashish Verma 與 Deep Patel